# 生产环境 Prometheus 监控系统部署指南(Linux)
# 概述与架构
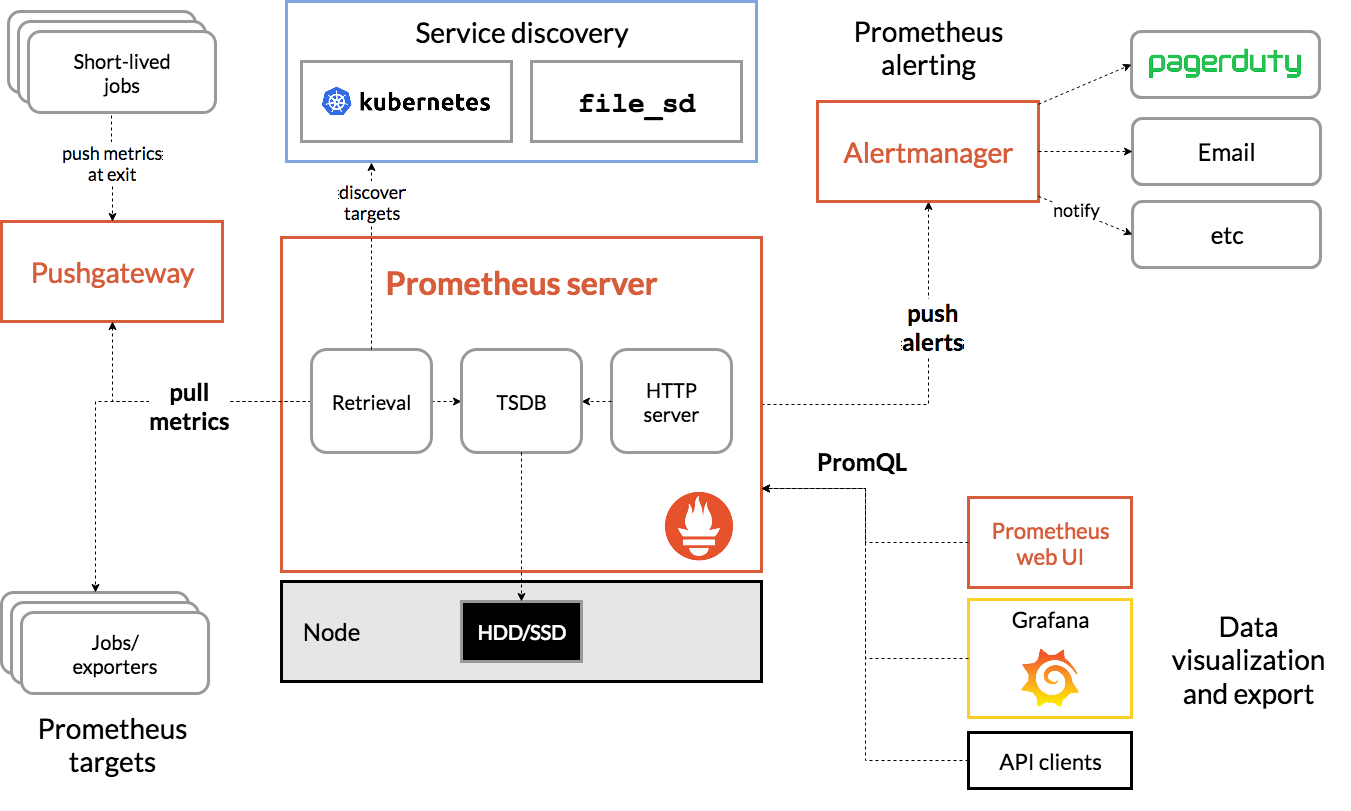
Prometheus 生态系统架构示意图:Prometheus Server 从各监控目标(Exporter 或应用)拉取指标数据,并可通过 Pushgateway 中转短生命周期任务的指标;根据定义的规则触发告警并推送至 Alertmanager;Grafana 等工具作为前端展示和可视化。
Prometheus 是云原生生态常用的开源监控告警系统,其核心由以下组件构成:
- Prometheus Server:负责定期从监控目标**拉取(pull)**指标数据,存储时序数据,并提供查询接口和简单 UI。同时根据预先配置的告警规则评估指标,当触发条件满足时生成告警事件。Prometheus 默认通过 HTTP 定期抓取各目标的
/metrics接口来收集数据。 - Pushgateway:用于辅助 Prometheus 获取无法被正常拉取的短生命周期任务或批处理作业的指标。短暂运行的任务可能在 Prometheus 下一次抓取前结束,无法直接被拉取;此时任务可以**主动推送(push)**指标到 Pushgateway,由 Pushgateway 缓存并暴露给 Prometheus 抓取。需要注意,Pushgateway 只是一个中转缓存,并不会将 Prometheus 完全变为推送模型。
- Alertmanager:Prometheus 的告警管理组件。Prometheus 根据规则触发告警后,会将告警事件推送给 Alertmanager 进行后续处理。Alertmanager 负责对告警进行去重、分组,并按照预先配置的路由将告警通知发送到指定渠道(如邮件、Slack、PagerDuty 或 Webhook 等)。它也是实现告警降噪和静默(Silence)的核心组件。
- Grafana:流行的开源可视化展示平台。Grafana 支持将 Prometheus 作为数据源,查询其时序数据,并以仪表盘形式图形化展示指标。同时 Grafana 提供了可视化告警功能,支持基于图表直接创建告警规则,通过自身的通知渠道(邮件、聊天工具等)发送告警通知。在本方案中,Grafana主要用于数据展示和辅助告警。
以上组件各司其职:Prometheus 专注于数据采集、存储和告警触发,Pushgateway 补充特殊场景的数据上报,Alertmanager 统一告警通知出口,Grafana 提供友好的可视化界面和报表。接下来将介绍在 Linux 环境下,如何安装部署这些组件并将其整合为完整的监控告警系统。
# Prometheus 服务器部署
# 功能与作用简介
Prometheus Server 是整个监控系统的核心。它通过配置的抓取规则定期从目标端点拉取指标数据,并将数据按时间序列存储在本地时序数据库中(默认为 leveldb 存储在磁盘)。Prometheus 支持灵活的查询语言 PromQL,用户可以查询和聚合监控数据。Prometheus 还可以根据告警规则评估指标数据,当某个条件满足阈值时触发告警,将告警信息发送给 Alertmanager 处理。Prometheus 自带一个简单的网页 UI 界面供直接查看数据和测试查询,但通常我们会结合 Grafana 来实现更丰富的可视化。
指标采集方式: Prometheus 默认采用 Pull 模式,即由 Prometheus 服务端主动去抓取各监控目标(Target)提供的指标接口。这要求 Prometheus 能直接网络访问到这些目标。常见做法是被监控应用暴露一个 HTTP /metrics 接口,或在目标主机上部署 Exporter。例如,为了监控 Linux 主机的系统指标,可部署官方的 Node Exporter,它在本机提供系统指标数据(CPU、内存、磁盘等)的接口供 Prometheus 抓取。Prometheus 可以通过静态配置或服务发现等方式知道这些目标的地址并定期抓取数据。除了 Pull 模式,对于那些无法长时间运行或网络不可达的短生命周期任务,则可以采用 Push 模式:任务在结束前将数据推送到 Pushgateway,Prometheus 再从 Pushgateway 拉取。Pull 和 Push 的结合使 Prometheus 在灵活性和可靠性上取得平衡。
数据存储与处理: Prometheus 将抓取到的样本数据存入本地时序数据库(TSDB)。默认数据保存在启动目录下的data/目录,支持通过启动参数自定义路径。Prometheus 是单机版数据库,不依赖外部集群存储,这让其在故障时更易于保持工作。Prometheus 还会按照全局evaluation_interval周期性执行告警规则的计算,一旦符合条件就生成告警并推送给 Alertmanager。
# 安装 Prometheus(Linux)
1. 下载与安装: Prometheus 官方以二进制形式发布,无需额外依赖。访问 Prometheus 官方下载页面获取最新版本的 Linux 压缩包并下载。例如,以 2.32.1 版本为例,可以使用命令:
# 假设使用 wget 下载 Prometheus 二进制包
VERSION=2.32.1
wget https://github.com/prometheus/prometheus/releases/download/v${VERSION}/prometheus-${VERSION}.linux-amd64.tar.gz
tar -xzf prometheus-${VERSION}.linux-amd64.tar.gz
mv prometheus-${VERSION}.linux-amd64 /usr/local/prometheus
上述命令将 Prometheus 解压到 /usr/local/prometheus 目录。进入该目录可以看到包含 Prometheus 可执行文件(prometheus)、命令行工具(promtool)、默认配置文件 prometheus.yml 以及自带的示例控制台页面等。
2. 创建运行用户与目录: 为提高安全性,建议创建独立的系统用户运行 Prometheus,并为数据存储等创建专用目录。例如创建名为 prometheus 的用户且无登录权限,并准备数据目录:
useradd -M -s /sbin/nologin prometheus
mkdir -p /data/prometheus
chown -R prometheus:prometheus /usr/local/prometheus /data/prometheus
上述命令在 /data/prometheus 下创建数据目录并赋予 prometheus 用户权限,用于存放 Prometheus 时序数据库数据。
3. 配置 Prometheus: Prometheus 主配置文件为 prometheus.yml(默认为当前目录下或通过参数指定)。打开该文件(例如路径 /usr/local/prometheus/prometheus.yml),根据需要修改全局抓取频率、告警配置和抓取目标等配置项:
全局参数: 可以调整
global下的参数,如scrape_interval抓取间隔(默认1m),evaluation_interval规则评估间隔等。例如设置全局抓取和评估间隔为 15秒:global: scrape_interval: 15s evaluation_interval: 15sAlertmanager 集成: 在配置文件中
alerting部分指定 Alertmanager 的地址,使 Prometheus 知道将告警发送到哪里。比如 Alertmanager 部署在本机默认端口9093,则添加:alerting: alertmanagers: - static_configs: - targets: ["localhost:9093"]说明: 可以配置多个 Alertmanager 实例实现高可用,Prometheus 将并行发送告警到所有配置的 Alertmanager。
规则文件: 为了管理告警和录用规则,Prometheus 支持将规则定义放在独立文件中,并在主配置中通过
rule_files包含这些文件。例如新建目录/usr/local/prometheus/rules/用于存放规则文件,然后在配置中加入:rule_files: - "/usr/local/prometheus/rules/*.yml"这样 Prometheus 会加载该目录下所有
.yml结尾的规则文件。在这些文件中可以定义告警规则(Alerting rules)和记录规则(Recording rules)。抓取目标(scrape_configs): 配置 Prometheus 要监控的目标列表。每个抓取任务称为一个 job,在
scrape_configs列表下配置。下面是几个示例配置:scrape_configs: - job_name: "prometheus" static_configs: - targets: ["localhost:9090"] - job_name: "linux-node" static_configs: - targets: ["localhost:9100"] # Node Exporter 默认在9100端口 relabel_configs: - source_labels: ["__address__"] regex: "(.*):.*" target_label: "instance" replacement: "$1" - job_name: "pushgateway" honor_labels: true static_configs: - targets: ["localhost:9091"]上述配置包含:① Prometheus 自身(作为监控目标,可抓取自身的指标用于自监控);② Linux Node Exporter(假设已在本机9100端口运行,用于采集主机系统指标);③ Pushgateway(用于抓取推送的指标)。Node Exporter job 中示例了使用
relabel_configs重写实例标签,去除端口号,仅保留主机名作为实例标识。Pushgateway job 设置了honor_labels: true,目的是保留由 Pushgateway 接收的指标中原始 job/instance 标签,避免被 Prometheus 默认赋予的 job 名覆盖。
配置完成后,可以使用 Prometheus 自带工具检查配置是否有效:/usr/local/prometheus/promtool check config prometheus.yml。确保没有错误后,准备启动服务。
4. 使用 systemd 启动 Prometheus: 为方便管理,将 Prometheus 注册为 systemd 服务。在 /etc/systemd/system/ 下创建服务单元文件 prometheus.service,内容示例如下:
[Unit]
Description=Prometheus Server
Documentation=https://prometheus.io/docs/introduction/overview/
After=network.target
[Service]
Type=simple
User=prometheus
Group=prometheus
ExecStart=/usr/local/prometheus/prometheus \
--config.file=/usr/local/prometheus/prometheus.yml \
--storage.tsdb.path=/data/prometheus \
--web.listen-address=0.0.0.0:9090 \
--web.console.libraries=/usr/local/prometheus/console_libraries \
--web.console.templates=/usr/local/prometheus/consoles
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
以上配置指定 Prometheus 以我们创建的用户运行,使用先前编辑的配置文件和数据目录,并监听在 0.0.0.0:9090(这样局域网内其他机器也可访问其接口;若出于安全考虑仅允许本机访问,可改为localhost:9090)。ExecReload 定义了重新加载配置的操作(向主进程发送 HUP 信号实现平滑重载)。保存文件后执行 sudo systemctl daemon-reload 加载新单元,然后启动并设置开机自启:
systemctl start prometheus
systemctl enable prometheus
启动成功后,可通过 systemctl status prometheus 查看运行状态,应看到 Prometheus 主进程已在监听9090端口。此时访问 http://<服务器IP>:9090/ 可以打开 Prometheus 自带的状态页面,验证抓取目标是否正常(Status -> Targets 页签下应列出配置的各个 job 及其抓取状态)。
# 配置抓取规则与告警规则
Prometheus 的核心配置已经就绪,下一步需要编写告警规则来实现自动告警通知,以及在必要时添加更多抓取目标。
定义抓取目标: 上面配置文件示例已经展示了如何添加抓取目标。对于生产环境,除了监控Prometheus自身,还应至少部署 Node Exporter 监控主机资源,以及针对业务应用部署相应 Exporter 或直接暴露指标接口。将这些目标按照上述格式加入 scrape_configs 列表中,并指定合适的抓取间隔等参数即可。Prometheus 支持静态配置(如以上示例)和服务发现机制。如果监控对象较多且动态变化,可以考虑使用服务发现插件或将目标列表写入文件然后使用 file_sd_configs 动态加载。
编写告警规则: 告警规则使用 PromQL 表达式定义触发条件。当 Prometheus 在评估周期内检测到表达式结果满足条件并保持一段时间后,就会触发告警事件并发送给 Alertmanager。告警规则通常放在单独的规则文件中(如前文配置的 /usr/local/prometheus/rules/ 目录下),以 YAML 格式编写。规则文件由多个分组(groups)组成,每个分组可以包含多条规则。示例如下(文件名例如 alert.rules.yml):
groups:
- name: example-alert-rules
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "实例 {{ $labels.instance }} 宕机"
description: "{{ $labels.job }} 中的 {{ $labels.instance }} 超过1分钟无法连通。"
- alert: HighCpuUsage
expr: avg(rate(node_cpu_seconds_total{mode!="idle"}[5m])) by (instance) > 0.9
for: 5m
labels:
severity: warning
annotations:
summary: "CPU 使用率过高 - {{ $labels.instance }}"
description: "{{ $labels.instance }} CPU五分钟平均使用率超过90%。"
第一条规则 InstanceDown 检测任意目标的存活状态指标up是否为0(表示无法抓取)持续1分钟,如果是则触发告警。第二条规则 HighCpuUsage 示例了一个针对 Node Exporter 指标的规则:计算非idle的CPU占用率五分钟平均值,如果超过90%持续5分钟则告警。labels.severity 用于给告警分级,比如区分严重程度,annotations 提供告警摘要和详细描述,其中可以使用模板变量插入标签和值。
注意: 编写规则后,需要让 Prometheus 加载新规则。如果按照上述配置使用了
rule_files包含规则文件,则可以通过 POST 请求触发热加载,例如执行:curl -XPOST http://localhost:9090/-/reload或者简单重启 Prometheus 服务。如果规则语法有误,Prometheus 会在日志中报错或拒绝加载,此时可借助
promtool check rules <文件>来验证规则文件的正确性。
配置并加载告警规则后,当被监控系统出现满足条件的异常情况时,Prometheus 会生成告警并将其发送给 Alertmanager 实现通知。下一节将介绍 Alertmanager 的部署和告警通知配置。
# Pushgateway 部署与应用
# 作用与适用场景
Pushgateway 的作用是充当指标数据的缓冲网关,用于收集那些无法被 Prometheus 直接拉取的指标。典型场景是短命任务(如一次性批处理、定时脚本),它们可能在 Prometheus 下次抓取之前就结束了,导致指标丢失。通过 Pushgateway,这些任务可以在结束前主动推送一次最新指标到网关,Prometheus 再从 Pushgateway 拉取,从而保证数据不遗漏。Pushgateway 将最近一次推送的指标缓存起来,直到下一次被更新或手动清除。需要注意:Pushgateway 并不聚合指标,也不会自动过期旧数据;设计上不实现指标 TTL,是为了避免误用 Pushgateway 做持续性数据存储。因此建议仅在必要场景下使用,对于常驻进程应尽量通过 Exporter 暴露指标,或者使用 Node Exporter 的 textfile 模式收集脚本输出。
# 安装与配置 Pushgateway
1. 安装启动: 从 Prometheus 官方下载页面获取 Pushgateway 的二进制发行版(pushgateway-X.Y.Z.linux-amd64.tar.gz),解压后将可执行文件放置到如 /usr/local/bin/ 目录。创建独立用户运行 Pushgateway(例如 pushgateway),然后编写 systemd 服务单元 /etc/systemd/system/pushgateway.service 如下:
[Unit]
Description=Prometheus Pushgateway
After=network.target
Wants=network-online.target
[Service]
Type=simple
User=pushgateway
Group=pushgateway
ExecStart=/usr/local/bin/pushgateway
Restart=on-failure
[Install]
WantedBy=multi-user.target
该单元配置以 pushgateway 用户运行 Pushgateway,默认监听在 0.0.0.0:9091 端口。保存后执行 systemctl daemon-reload,然后启动服务并设置开机启动:
systemctl start pushgateway
systemctl enable pushgateway
启动后,可通过 curl http://localhost:9091/metrics 验证 Pushgateway 是否工作。初始情况下返回的只是 Pushgateway 自身的一些运行指标。
2. 将 Pushgateway 纳入 Prometheus 抓取: 在 Prometheus 的配置文件中新增一个抓取任务,使其定期从 Pushgateway 获取数据(这一部分前面已经在 Prometheus 配置中示例过)。关键是设置 honor_labels: true 保留任务推送时附加的标签,避免所有指标都被视为来自 Pushgateway 本身。配置完成后重载 Prometheus 配置。Prometheus Target 列表中应出现 Pushgateway,状态为 UP 表示连接正常。
3. 推送指标到 Pushgateway: 应用程序或脚本需要使用 Prometheus 提供的客户端库或HTTP接口,将指标发送到 Pushgateway。Pushgateway 接口格式通常为:POST http://<pushgateway>:9091/metrics/job/<job_name>[/<label>/<value>...],在请求体中以 Prometheus 文本格式提供指标数据。例如,一个shell脚本在完成时可以用curl命令:
echo "my_batch_job_duration_seconds 12.7" | curl --data-binary @- http://localhost:9091/metrics/job/mybatch/instance/$(hostname)
这会将指标 my_batch_job_duration_seconds 值 12.7 推送到 Pushgateway,带有 job="mybatch" 和本机主机名作为 instance 标签。随后 Prometheus 在下次抓取时就能获得该指标样本。Pushgateway 默认会将上一次推送的结果保留,直到有新的推送覆盖或通过 HTTP API 手动删除。因此对于一次性任务,建议在成功推送后通过调用 DELETE /metrics/job/<job_name>/instance/<instance> 来清理,防止过期数据长时间滞留(根据实际需要决定,Prometheus 也可通过 absent() 函数检测长期未更新的指标)。
通过以上部署与配置,Prometheus 已经可以通过 Pull 模式获取 Pushgateway 缓存的指标,实现对短暂任务的监控。Pushgateway 一般不需要复杂配置,其作用单一明确。在生产环境中,请确保限制可以访问 Pushgateway 推送接口的来源(例如通过防火墙或网关认证),以防止不可信任的指标数据注入。
# Alertmanager 部署与告警通知
# 主要功能原理
Alertmanager 是 Prometheus 体系中的告警集中处理组件。当 Prometheus 根据告警规则触发告警时,会将告警事件发送给 Alertmanager。Alertmanager 对接收到的告警进行如下处理:
- 分组(Grouping): 根据配置将相似的告警聚合成一条通知,以减少噪音。例如可以按告警的某些标签(如服务名、环境等)分组。
- 抑制(Inhibition): 支持设置告警抑制规则,当某些高严重级别告警触发时,自动抑制掉与之相关的低级别告警,避免层出不穷的次要告警。
- 静默(Silences): 提供静默功能,可以临时屏蔽特定告警(按标签匹配)在一段时间内不再通知,常用于维护窗口期间避免误报。
- 路由与通知: 按照预先配置的路由规则,将告警分派给不同的接收器(Receiver)。每个接收器定义了一种通知方式,如邮件、Slack消息、PagerDuty事件、Webhook调用等。可以为不同的告警类别配置不同的通知渠道和方式。
Alertmanager 默认监听在端口 9093,提供Web界面查看当前活跃告警和静默配置等。它也支持高可用部署:可运行多个 Alertmanager 实例构成集群,相互之间通过 Gossip 协议交换状态,实现告警通知的容错(HA 配置需在启动参数中指定集群监听和仲裁地址)。本指南以单实例为例介绍。
# 安装 Alertmanager(Linux)
1. 下载与安装: 从 Prometheus 官方获取 Alertmanager 最新二进制包(例如alertmanager-0.25.0.linux-amd64.tar.gz),解压后移动到 /usr/local/alertmanager 目录:
VERSION=0.25.0
wget https://github.com/prometheus/alertmanager/releases/download/v${VERSION}/alertmanager-${VERSION}.linux-amd64.tar.gz
tar -xzf alertmanager-${VERSION}.linux-amd64.tar.gz -C /usr/local/
mv /usr/local/alertmanager-${VERSION}.linux-amd64 /usr/local/alertmanager
目录下包含 alertmanager 可执行文件和默认配置文件等。创建专用用户:
useradd -M -s /sbin/nologin alertmanager
mkdir -p /var/lib/alertmanager
chown -R alertmanager:alertmanager /usr/local/alertmanager /var/lib/alertmanager
这里 /var/lib/alertmanager 将用来持久化 Alertmanager 的状态(如已发送通知日志、静默列表等),以免单实例重启后丢失信息。
2. 配置 Alertmanager: 打开主配置文件 /usr/local/alertmanager/alertmanager.yml,编写告警路由和接收方式。下面提供一个包含邮件通知配置的示例:
global:
resolve_timeout: 5m
# SMTP 邮件服务器配置(全局默认)
smtp_smarthost: 'smtp.example.com:587'
smtp_from: 'alerts@example.com'
smtp_auth_username: 'alerts@example.com'
smtp_auth_password: '邮箱登录密码或授权码'
route:
group_by: ['alertname']
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
receiver: 'team-email'
receivers:
- name: 'team-email'
email_configs:
- to: 'dev-team@example.com'
# 这里可以指定 from、smarthost 等,否则使用 global 默认值
send_resolved: true
以上配置含义如下:
global段设置了邮件发送的 SMTP 服务器信息。smtp_smarthost指定SMTP服务地址和端口(如企业邮箱或公共邮箱服务提供商的SMTP地址),smtp_from是发件人地址(通常和认证用户相同),接下来提供 SMTP 的认证用户名和密码。resolve_timeout则定义了告警被自动标记为已解决的超时时间(5分钟,如果Prometheus在此期间未再次触发该告警则认为其已恢复)。route段定义了告警路由策略。以上例子将所有告警统一路由(因为没有使用match筛选)到接收器team-email。group_by: ['alertname']表示按告警名称分组,相同告警类型的会合并通知;group_wait表示在收到首个告警后等待30秒以便收集可能的同组其他告警再一并通知;group_interval表示同一分组内后续告警每5分钟再通知一次;repeat_interval表示即使告警内容不变,经过4小时会重复通知一次(防止长时间没人处理时漏掉)。receivers段定义具体的告警接收方式。此处定义了名为team-email的接收器,使用email_configs发邮件。to填写收件人邮箱地址,可以是单个地址也可以是邮件列表。因为 global 已经定义了 smtp from 和主机,这里无需重复。send_resolved: true表示当告警恢复时也发送通知邮件。
配置完成后,可以运行 Alertmanager 自带的检查命令验证:/usr/local/alertmanager/amtool check-config /usr/local/alertmanager/alertmanager.yml。若无误即可启动服务。
3. 启动 Alertmanager 服务: 创建 systemd 单元文件 /etc/systemd/system/alertmanager.service:
[Unit]
Description=Prometheus Alertmanager
After=network.target
[Service]
Type=simple
User=alertmanager
Group=alertmanager
ExecStart=/usr/local/alertmanager/alertmanager \
--config.file=/usr/local/alertmanager/alertmanager.yml \
--storage.path=/var/lib/alertmanager
Restart=on-failure
[Install]
WantedBy=multi-user.target
启用并启动服务:
systemctl daemon-reload
systemctl start alertmanager
systemctl enable alertmanager
启动后访问 Alertmanager 的Web界面(例如 http://<服务器IP>:9093),可以查看当前没有活跃告警。在 Alertmanager 界面也可以手动创建静默以屏蔽某些告警。
4. 集成 Prometheus 与测试告警: 确保 Prometheus 配置中的 alerting.alertmanagers 已指向 Alertmanager 地址(如先前配置的localhost:9093)。当 Prometheus 触发告警时,在 Alertmanager 控制台的 Alerts 页面应能看到告警列表,并根据我们的配置通过 Email 发送通知。可以通过故意停止某个Exporter进程,触发InstanceDown告警来验证邮件通知是否正常送达。收到邮件后注意检查邮件服务器是否被标记为垃圾邮件等,并据此调整邮件内容或SMTP设置(例如使用公司内部邮件服务器或调整 Grafana/Alertmanager 的邮件模板)。
提示: 若使用公共邮箱(如 Gmail)作为 SMTP 发信,可能需要在邮箱账户中启用“应用专用密码”或降低安全设置,以允许第三方应用发送邮件。另外,Alertmanager 也支持与企业微信、钉钉、Slack 等多种渠道集成,可根据需要进行扩展配置。
通过 Alertmanager,运维人员可以接收到来自 Prometheus 的告警通知,并结合 Alertmanager 提供的分组和静默等功能减少无效告警干扰。告警通知的策略和内容可根据团队需求灵活调整。
# Grafana 部署与集成
# Grafana 的作用
Grafana 是目前业界常用的可视化监控平台。相对于 Prometheus 自带的简易图表,Grafana 提供了丰富的图表组件、自定义面板和仪表盘布局,以及用户权限管理和团队协作功能。在本监控系统中,引入 Grafana 主要有两个目的:
- 数据可视化展示: 将 Prometheus 采集的指标数据通过 Grafana 仪表盘直观地展示出来,包括折线图、柱状图、饼图等多种形式。Grafana 允许将多个相关指标组合在一个仪表盘页面,方便从不同角度观测系统状态。此外,社区提供了大量现成的仪表盘模板,可以直接导入使用。例如官方提供的 Node Exporter 全方位主机监控仪表盘等,大大减少了自行配置的工作量。
- 图形化告警: Grafana 提供自身的告警功能。从 Grafana 8 版本开始,引入了统一的告警中心,可基于任意数据源的查询结果设置告警条件。运维人员可以直接在图形界面上选中某个图表的指标,设定阈值和持续时长,配置通知渠道(支持邮件、Slack、Webhook 等),Grafana 将负责评估和发送告警通知。这种方式直观易用,特别适合对可视化阈值调整有需求的场景。不过需要注意,Grafana 的告警与 Prometheus 的 Alertmanager 是彼此独立的体系:您可以选择使用 Prometheus+Alertmanager 方案,也可以使用 Grafana 自身的告警,或两者结合。其中 Prometheus+Alertmanager 适合集中管理大规模告警策略,而 Grafana 适合对特定仪表盘进行临时或个性化告警配置。
# 安装 Grafana(Linux)
Grafana 可以通过多种方式安装:官方提供了 Linux 二进制包、Docker 镜像,以及适用于主流发行版的 APT/YUM 仓库。本指南以二进制包方式为例。
1. 下载与用户设置: 前往 Grafana 官方网站或 GitHub Releases 获取相应版本的 Linux 压缩包(例如 grafana-9.3.6.linux-amd64.tar.gz)。下载后解压到目标目录:
wget https://dl.grafana.com/enterprise/release/grafana-9.3.6.linux-amd64.tar.gz
tar -zxvf grafana-9.3.6.linux-amd64.tar.gz -C /usr/local/
mv /usr/local/grafana-9.3.6/ /usr/local/grafana
以上将 Grafana 安装在 /usr/local/grafana。接着创建运行用户并准备数据目录:
useradd -M -s /sbin/nologin grafana
mkdir -p /data/grafana
chown -R grafana:grafana /usr/local/grafana /data/grafana
2. 配置 Grafana: Grafana 的默认配置文件为 conf/defaults.ini(或grafana.ini,取决于版本)。通常默认配置即可满足使用,但我们可以做以下调整:
修改数据存储路径:默认 Grafana 将数据(比如数据库、日志、插件等)存放在安装目录下的
data/子目录。为方便管理,我们可以在配置中指定自定义路径,例如上面创建的/data/grafana。打开/usr/local/grafana/conf/defaults.ini,在[paths]部分修改:[paths] data = /data/grafana/data logs = /data/grafana/log plugins = /data/grafana/plugins这样 Grafana 运行时会将 SQLite 库等保存在
/data/grafana/data下。(可选)配置 Grafana SMTP:如果计划使用 Grafana 的告警邮件通知功能,需要在配置文件的
[smtp]部分设置邮件服务器,例如:[smtp] enabled = true host = smtp.example.com:587 user = alerts@example.com password = 邮箱密码或授权码 from_address = grafana_alerts@example.com并在
[alerting]部分确保enabled = true。这样 Grafana 才能通过SMTP发邮件。通常使用 Grafana GUI 配置告警联系点时会引用这里的 SMTP 设置。
修改完配置后,保存文件。
3. 配置 systemd 服务并启动: 在 /etc/systemd/system/ 下创建 grafana.service(或 grafana-server.service):
[Unit]
Description=Grafana Server
After=network.target
[Service]
Type=simple
User=grafana
Group=grafana
ExecStart=/usr/local/grafana/bin/grafana-server -homepath /usr/local/grafana
Restart=on-failure
[Install]
WantedBy=multi-user.target
注意: 如果是通过官方仓库安装(如
apt install grafana),会自带名为grafana-server.service的单元文件,其 ExecStart 通常为/usr/sbin/grafana-server --config=/etc/grafana/grafana.ini ...等参数,并默认以grafana用户运行。上面我们使用二进制安装,自行配置了路径和用户。
加载新服务并启动:
systemctl daemon-reload
systemctl start grafana
systemctl enable grafana
Grafana 默认监听在 3000端口。启动成功后,在浏览器访问 http://<服务器IP>:3000,应看到 Grafana 登录页面。默认登录用户名和密码都是 admin,首次登录会提示修改密码。
# 添加 Prometheus 数据源与仪表盘
登录 Grafana 后,现在将 Prometheus 接入:
添加数据源: 点击左侧菜单的齿轮图标 (Configuration) -> Data Sources -> Add data source,选择 Prometheus 类型。在 URL 栏填入 Prometheus 的访问地址,例如
http://localhost:9090(如果 Grafana 与 Prometheus 部署在同一台服务器且未对外,这里可以用 localhost)。其他项保持默认,点击 Save & Test 测试连接成功。成功后,Prometheus 就作为数据源添加到了 Grafana 中。导入仪表盘: Grafana 官方和社区提供了许多现成的 Dashboard 模板。例如,要导入 Node Exporter 的服务器监控仪表盘,可在 Grafana.com 查找 Dashboard ID(如 1860 是常用的Node Exporter Full仪表盘)。在 Grafana 界面点击 “+” -> Import,输入仪表盘ID或JSON,然后选择刚添加的 Prometheus 数据源并导入。很快就能看到系统各项指标的丰富图表。也可以手动新建仪表盘:点击 “+” -> Dashboard -> 添加一个新面板,根据需要选择指标和可视化类型,应用 PromQL 查询语句。例如添加一个折线图面板展示
node_load1(1分钟平均负载)指标走势。组织和权限: 可以将多个面板排版在一个Dashboard页面,并保存仪表盘。Grafana 支持创建文件夹来归类仪表盘,以及为团队或用户分配只读或编辑权限等,这对于多人协作很有用。
通过 Grafana 的仪表盘,监控数据得到了直观的展示。相较于直接查看 Prometheus 的数值,Grafana 的图表和历史趋势更利于发现异常和分析问题。
# Grafana 告警配置(可视化告警)
除了展示功能,我们也可以利用 Grafana 实现告警,以达到“所见即所得”的效果。在 Grafana 8+版本中,告警功能整合到了 Alerting模块,支持独立于面板的告警规则管理:
设置通知渠道(Contact Point): 在 Grafana 左侧菜单选择 Alerting (警报铃铛图标) -> Contact points。点击 New contact point 新建,例如选择 Email,填入收件人地址。如果之前未配置SMTP,此处会提示需要配置 SMTP 设置 (opens new window)。通知渠道也可以是 Slack、Webhook 等,根据需要设置。保存后,此联系点可用于告警分发。
创建告警规则: Grafana 支持在仪表盘编辑模式下为某个图表直接创建告警,或者通过 Alerting -> Alert rules 页面集中管理。这里以仪表盘面板为例:编辑某指标图表,在右侧Alert选项卡创建告警。设定告警名称、评估频率,添加条件(Condition):例如选择查询A的数值,当
avg() > 0.9持续5分钟则触发(这类似PromQL表达式的图形界面设置)。分配通知,把上一步创建的Email联系点加入。当保存仪表盘后,这个告警规则即开始生效。告警管理: 在 Alerting -> Alert rules 页面可以看到所有规则及其当前状态。Grafana 定期根据规则评估数据,一旦触发将在 Alerting -> Alert instances 列出告警实例,并通过配置的渠道发送通知(例如邮件)。Grafana 还提供 Alert history 日志,方便追踪过去发生的告警。
通过 Grafana 的图形化告警,用户无需手写 PromQL 就能基于可视化的指标设置告警,对一些临时监控需求或不方便在Prometheus集中配置的告警特别有用。但应注意Grafana告警适用于数据源查询可用的前提,如果 Prometheus 宕机或网络不通,Grafana 将无法评估 Prometheus 数据源的规则,因此关键告警仍建议由 Prometheus+Alertmanager 执行,以减少链路依赖。
# 推荐目录结构与配置示例
综合以上部署步骤,下面给出各组件在 Linux 系统上的推荐安装目录结构以及主要配置文件示例,供参考:
/usr/local/prometheus/ # Prometheus 安装目录
├── prometheus # 主程序可执行文件
├── promtool # 命令行工具
├── prometheus.yml # Prometheus 主配置文件
├── consoles/ # 内置控制台页面模板
├── console_libraries/ # 内置控制台页面库
└── rules/ # (新建)规则文件目录
└── alert.rules.yml # 示例告警规则文件
/data/prometheus/ # Prometheus 数据目录(TSDB 存储)
/usr/local/alertmanager/ # Alertmanager 安装目录
├── alertmanager # 主程序
└── alertmanager.yml # Alertmanager 配置文件
/var/lib/alertmanager/ # Alertmanager 数据目录(存储静默等状态)
/usr/local/bin/pushgateway # Pushgateway 可执行文件(可放于bin目录)
(Pushgateway 无单独配置文件,如需持久化可增加参数指定数据文件路径)
/usr/local/grafana/ # Grafana 安装目录
├── bin/grafana-server # Grafana 主程序
└── conf/grafana.ini # Grafana 主配置文件(defaults.ini)
/data/grafana/ # Grafana 数据目录
└── (data, logs, plugins 等子目录按配置生成)
# systemd 服务单元文件目录:
/etc/systemd/system/
├── prometheus.service
├── alertmanager.service
├── pushgateway.service
└── grafana.service
上面的结构中,二进制程序和配置放置在 /usr/local 下,各组件的数据文件放在 /data 或 /var/lib 下,便于备份和管理。实际环境中可根据规范调整路径,例如将配置文件放到 /etc/prometheus/ 等,但要注意同步更新启动参数指定正确路径。
Prometheus 配置文件示例(prometheus.yml):
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
rule_files:
- "rules/*.yml"
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "node_exporter"
static_configs:
- targets: ["localhost:9100"]
- job_name: "pushgateway"
honor_labels: true
static_configs:
- targets: ["localhost:9091"]
该配置指定 Prometheus 每15秒抓取一次目标、评估一次规则;告警将发送至本机9093的Alertmanager;加载rules目录下所有规则文件;配置了三个抓取任务:自身、Node Exporter 和 Pushgateway。
示例告警规则文件(rules/alert.rules.yml):
groups:
- name: example
rules:
- alert: InstanceDown
expr: up == 0
for: 1m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} is down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for 1 minute."
这个规则与前文类似,用于检测任意抓取目标失联1分钟并告警。可根据需要增加更多规则。
Alertmanager 配置文件示例(alertmanager.yml):
global:
smtp_smarthost: 'smtp.example.com:25'
smtp_from: 'alert@mycompany.com'
smtp_auth_username: 'alert@mycompany.com'
smtp_auth_password: 'password'
route:
group_by: ['alertname']
receiver: 'default-mail'
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
receivers:
- name: 'default-mail'
email_configs:
- to: 'dev-team@mycompany.com'
此配置将所有告警按照 alertname 分组后,通过邮件发送给开发团队。请根据实际 SMTP 服务调整端口和认证信息。完成上述配置并运行后,当 Prometheus 触发例如 InstanceDown 告警时,Alertmanager 会在 group_wait 时间后将告警通过邮件发送。
Grafana 配置重点: Grafana 通常在安装后通过其Web界面完成配置,这里主要确保 grafana.ini 中 [paths] 和 [smtp] 等已正确设置。首次登录Grafana后,请尽快更改管理员密码,并根据需要创建组织、用户等。
# 总结
通过以上步骤,我们在 Linux 环境下搭建了完整的 Prometheus 监控告警系统,包括 Prometheus 核心、Pushgateway 辅助、Alertmanager 告警管理以及 Grafana 可视化组件。Prometheus 周期性采集各类指标数据并评估告警规则,将异常上报给 Alertmanager;Alertmanager 实现了多渠道告警通知,确保第一时间发现问题;Grafana 则提供了统一的监控视图和人性化的操作界面。整套系统通过 systemd 以服务方式运行,方便在生产环境管理。后续可以根据业务需要扩展更多 Exporter、完善告警规则策略,并利用 Grafana 打造定制的监控大屏。至此,生产级别的监控告警平台已经就绪,为系统稳定保驾护航。